When I use Browser and go on wikileaks.org or wikipedia.org it partially works. If I click on links presented it works without a problem, but if I type something in search field and press “search” it gets stuck in “loading” mode until VM disconnects.
The Web Browser UI dApp, while being just an ‘app’ it is is one of the most sophisticated components of the system, once you take the system-intrinsic proxy apparatus into consideration. Also, the dynamic JavaScript requests interception mechanics running right within of the web-browser.
Lots and lots of resources have been spent to allow for the current experience.
The sub-system does its best to trick both the native web-browser and the target web-server into believing in a variety of things. It might be the most sophisticated web-proxy apparatus ever developed.
-
It acts at the TCP level to reconstruct the entire data stream coming from the web-server.
-
Then at the level of HTTP 1.1 protocol to reconstruct all the HTTP 1.1 chunks (if HTTP 1.1 chunked encoding is being used, the fact is detected autonomously)
-
It attempts to perform various content detections to decide whether URL rewriting is to be taking place. The point of URL rewriting is to make sure all the assets referenced from the webpage make their way through one of the nodes comprising the GRIDNET network.
-
All the requests from the client computer, meaning your web-browser are checked. All the privacy related HTTP headers (web browser version, screen resolution etc.) these are stripped and/or replaced.
-
GRIDNET proxy servers are capable of maintaining HTTP 1.1 persistent connections while multiplexing these across connections made by your web-browser.
-
GRIDNET proxy servers do their best to associate data-requests coming from your web-browser to already established HTTP 1.1 connections with remote servers if relative URLs are in use.
-
proxy servers support I believe every compression algorithm used across the Internet with custom implementation of these. We need to be rewriting URLs of assets so as to make sure all the data flows through proxy server. The target web-server might be delivered data chunked at the a) TCP layer b) HTTP layer c) the data might be compressed. So what we do, we reconstruct all the TCP data packets, we reconstruct all the HTTP chunks, we decompress the data (gZip, Brotli etc.). If the system detects the data to comprise, say, a video/audio stream, no processing would be taking place and the system would prioritize performance and use direct memory pass-through.
-
Then, the data gets compressed back again and is sent to your web-browser. From the viewpoint of the web-browser, it thinks the Web Browser UI dApp is rendering some custom HTML. It has no idea an external website is being displayed. That is how mitigate all the cross-site scripting security mechanics of Chromium. Also effectively performing a man-in-the middle attack across your web-browser and the target web-server, establishing an encrypted TLS tunnel.
-
Other interesting points to note. The system effectively is capable of tricking most if not all the Chromium’s CORS-policy-related pre-flight checks. So once Chromium asks one of the proxy servers whether the server agrees to be delivering data once accessed from the URL you happen to be accessing the full-node from, the full-node would impersonate the target web-server and say that it agreed.
It is state-of-the art in http-web-proxies. I believe it is. BUT… it is not perfect. We’ve got the entire web to cover and things MIGHT get tricky.
- Websites need to perform dynamics HTTP queries, XML queries etc. That’s probably how Wikipedia performs its searches. To cope with this the Web-browser UI dApp injects Javascript code into every visited web-page. The injected payload is to hijack any dynamic JavaScript-based data queries. We have tested it across a variety of websites but I suppose that’s where troubles lie.
The history traversal mechanics also are accomplished though custom code. Now I know that folks lead by PauliX also did some crazy addons allowing for customization of websites.
@PauliX please take over.
Ok the expected time for me to take a look around these issues would be around 24-48 hours.
I was able to reproduce the issue. After searching for a ‘cat’ (I love kitties!).
The browser hang as seen below.
Taking a closer look at some of the internals in Chromium Dev Tools, we can notice what follows:

The internal dynamic data-requests’ interception engine came up with an invalid target URL.
I’m on it.
OK, so I’ve been researching the issue little but further.
I have stumbled upon one more thing, which was related to the internal DNS sub-system, another thing was that the internal reverse CORS-proxy apparatus was listening on the public IP, one assigned by node’s operator, instead of the ‘any’ address i…e ‘0.0.0.0’.
I have proceeded and fixed the above issues at full-node software (GRIDNET Core).
The Reverse CORS proxy apparatus should be now easily accessible by both node’s domain ex. 'test.gridnet.org. and its IP address.
An interesting thing to note is that once can use the proxy apparatus entirely detached from the rest of the system.
ex. one may try to head over to an anonymized version of Wikipedia by going directly to this URL:
https://test.gridnet.org:444
What we may do in the future is to make the reverse cors proxy apparatus available through a specially pre-fixed URL directly at port 433, to omit firewalls even better.
It is already being done for web-sockets and webrtc connections so I do not see any reason why it would not be possible with web-routing.
Of course I know that there is some work-overhead associated as we would need to disintegrate the ‘proxy server’ and make everything flow yet again through the main ‘web-socket’ at port 433.
Anyway! as for the problem/bug at hand.
It was not really related to the dynamic URL rewriting! I mean it was… but not with the more sophisticated data-requests’ interception engine.
It was somewhere in the midst of these.
I’m now able to find some information about kitties.
That’s as far as Wikipedia goes.
Anyway… I’m still seeing errors in Chromium’s dev Tools… some URLs are still being translated the wrong way… and most worryingly few times I’ve noticed data in responses having data integrity errors… that would indicate trouble at full-nodes (C++, not my realm) @CodesInChaos.
Anyway… I’m proceeding with further. Wish me luck.
Update:
I went ahead and further improved some handling of some edge-case scenarios at the level of the Wizardous iFrame (it has to do we facilitating URL-rewrites), ex should handle cases where JavaScript code on a target website decided to dynamically formulate an HTTP post/get redirect. Wikipedia seemingly has done that in some cases.
Update 2:
I’ve further improved URL rewrite heuristic to account for cases where Wikipedia generates URLs in the form of ‘xyz.abc’, without a schema included (https:// or http://) so the dynamic URL rewrite engine treats these and non-relative as well.
Update3:
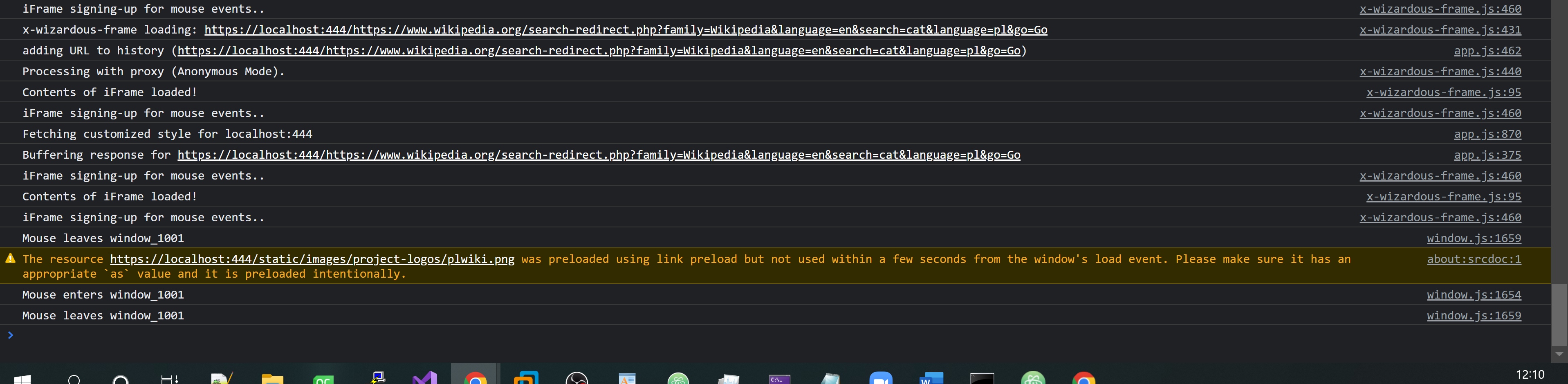
I can now look up information about kitties without seeing any errors appearing in the Chromium’s Dev Console
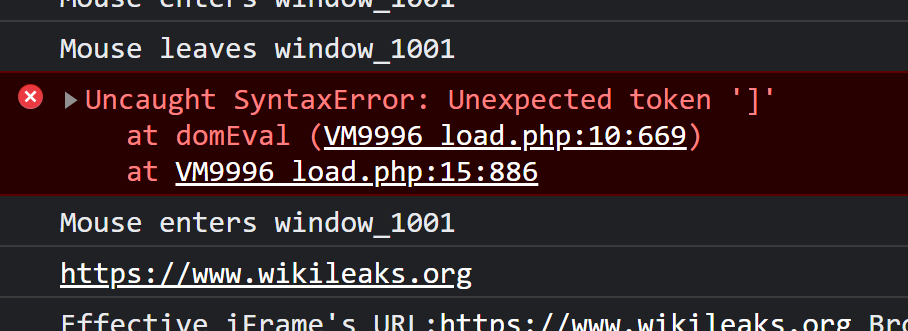
@CodesInChaos That’s happening at Core though…
Now, since the bug-reported tackled Wikileaks’ search as well…
The fixes I’ve introduced while fixing support of Wikipedia, seemingly were enough to cover for Wikileaks as well.
I’m calling it a day.
Few months ago, here at the Core Team, we’ve spent lots and lots of time making sure the proxy apparatus works as intended. We’ve streams lots and lots of data back and forth, tweaking performance and stuff, with double, even tripple buffering of data, supporting all the compression types encountered in the wild…
In the end, it passed all the automated tests.
I propose we continue monitoring the situation.
Should more error appear I would open an internal ticket gather a few folks and have all this validated all over again.
As of now, the integrity seems ‘solid enough’ i.e. >99% of the time.
Yes, definitely, all in all everything certainly works. I’ve just downloaded a 100MB large file through the ‘proxy-services’ and all the integrity was verified successfully.
@Major gave me a call today. Said that could not open-up his MIT-based homepage within the Browser UI dApp. I was given 72 hours to fix that. Anyway, I’ve managed within 2. The tweaks I’ve introduced also improved compatibility with lots of other web-servers among which I’ve discovered IEEE’s website to be now viewable as well.
The issue was with how the URL passed on to GET requests was being formulated.
Below, the MIT’s website proxied through our apparatus, that includes the video stream as well (notice the video source of the HTML5 video tag).
oh oh oh! Look at that (…) I didn’t know you were such a docile kitty…
oh well… guess one needs to be a ‘@Major’…